Github : https://github.com/fishbob889/local-llm-manager
隨著開源大型語言模型 (LLM) 的爆發,硬碟裡堆滿了各式各樣的 .safetensors 和 GGUF 檔案。原本使用指令行 (huggingface-cli) 下載模型雖然快速,但隨著模型數量增加,管理變得一團混亂:不知道哪個資料夾是做什麼的、檔案多大、何時下載的。
所以,開發一個 Local LLM Manager。這是一個輕量級、無需資料庫 (No-Database)、前後端分離的 Web 管理介面,專門用來管理與下載 Hugging Face 模型。
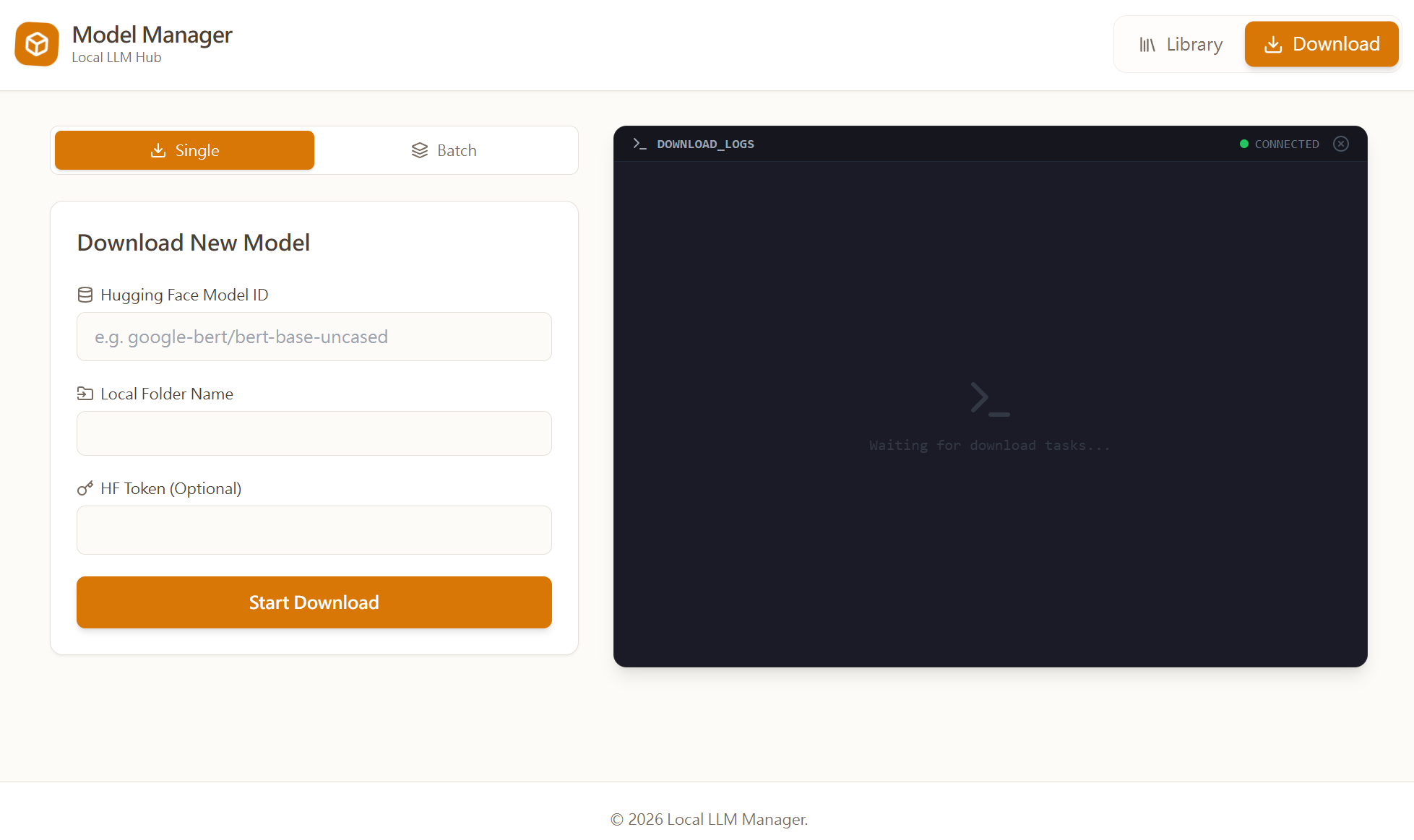
專案重點:
-
視覺化模型庫 (Library):以卡片式介面瀏覽本地模型,支援依大小、日期、名稱排序。
-
即時下載監控:整合 Python 下載腳本,透過 WebSocket 將進度條即時串流到網頁前端(駭客風格終端機介面)。
-
批次下載 (Batch Download):支援一次貼上多個 Model ID,自動排程佇列下載。
-
中繼資料管理:可直接在網頁上編輯模型說明 (
description.txt),資料隨檔案夾帶著走。 -
暖色系 UI 設計:採用 Tailwind CSS 打造舒適的 Latte/Paper 風格。
-
安全部署:整合 Nginx Proxy Manager (NPM) 與 Basic Auth 保護。
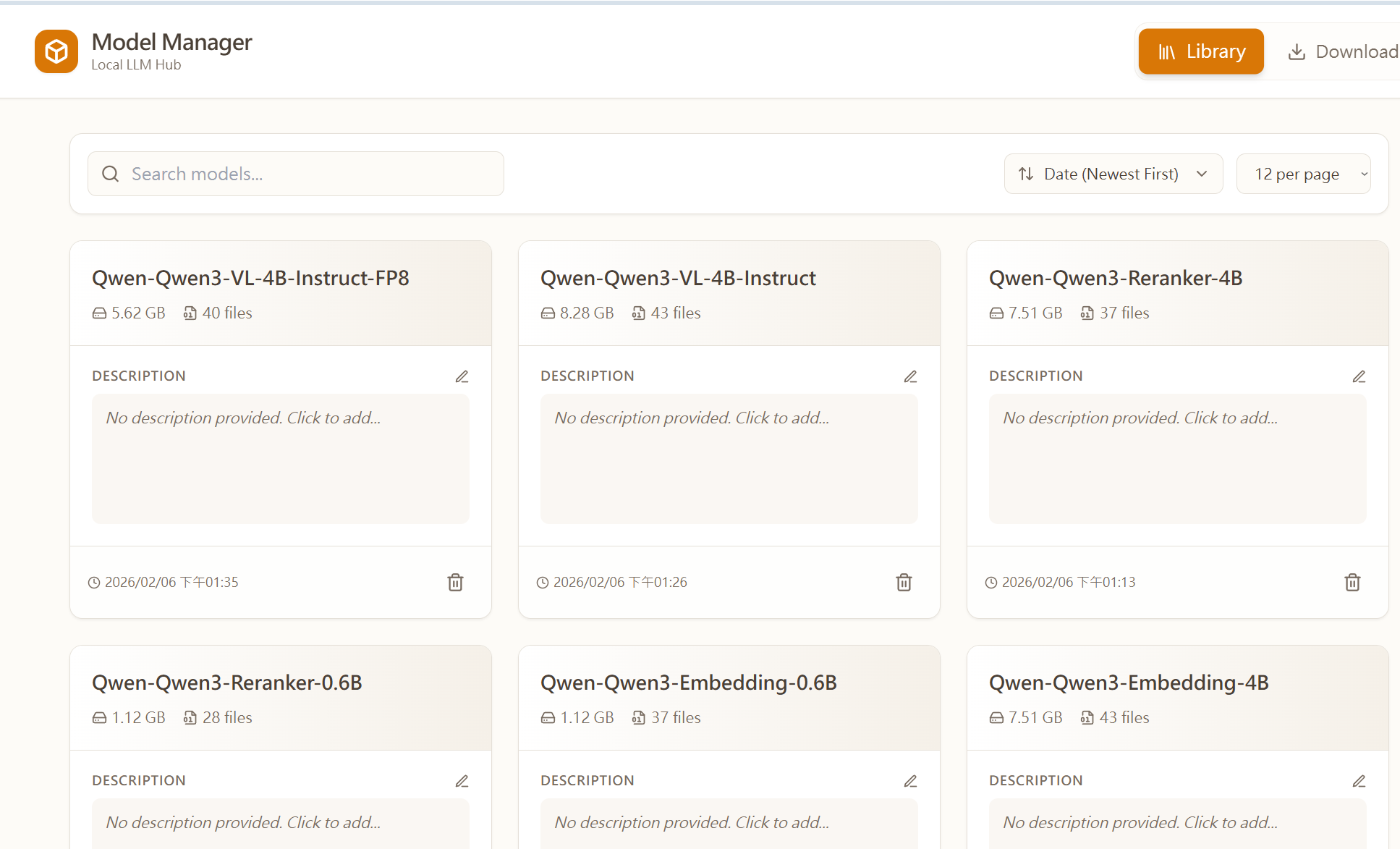
系統架構
為了保持系統輕量且易於遷移,採用了 「檔案即資料庫 (File-system as Database)」 的設計哲學:
-
Frontend: React (Vite) + Tailwind CSS + Lucide Icons
-
Backend: Node.js (Express) + WebSocket (
wslibrary) -
Worker: Python (
huggingface_hubSDK) 負責實際下載任務 -
Infrastructure: Docker Compose (Multi-stage build) + Nginx Proxy Manager
架構圖
-
使用者 透過瀏覽器存取 React 前端。
-
前端 發送 API 請求給 Node.js 後端。
-
後端 掃描
/data/models掛載目錄,即時計算資料夾大小與讀取說明檔。 -
下載時,Node.js 呼叫 Python 子程序 (Spawn Process)。
-
Python 輸出 Log,Node.js 透過 WebSocket 將 Log 廣播回前端顯示。
開發過程中的技術挑戰與解法
過程中,遇到了幾個有趣的技術坑,以下是解決方案:
1. WebSocket 訊息風暴 (Message Storm)
問題:Hugging Face 的下載進度條更新頻率極高(每秒數十次),直接轉發給前端會導致 Nginx 緩衝區溢位或瀏覽器卡頓,最終導致連線中斷 (DISCONNECTED)。
解法:在 Node.js 後端實作 「節流機制 (Throttling)」。 我們設定一個 500ms 的緩衝時間,只有當錯誤發生或距離上次廣播超過 500ms 時,才發送進度更新。這樣既保留了進度感,又保護了連線穩定性。
JavaScript
// Backend 節流邏輯片段
if (isError || (now - lastBroadcastTime > 500)) {
lastBroadcastTime = now;
broadcast({ ... });
}
2. Nginx 反向代理的中斷問題
問題:即使後端修好了,下載大模型時(如 70GB 的 Llama-3),連線依然會莫名中斷。
解法:這是 Nginx 的設定問題。必須在 Nginx Proxy Manager 中明確開啟 WebSocket 支援,並延長超時設定:
Nginx
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 3600s; # 關鍵:防止長連線被切斷
3. React 批次下載的競態條件 (Race Condition)
問題:在實作「批次下載」功能時,使用者貼上清單後立刻點擊開始,卻發現佇列是空的。原因是 React 的 useState 是非同步更新的,狀態還沒寫入,程式碼就先執行了。
解法:不依賴 State 的更新結果,而是直接將 e.target.value (使用者的原始輸入) 傳遞給解析函式,確保資料的一致性。
4. 排序功能的陷阱
問題:在前端進行「按大小排序」時,結果是錯的。原因是 API 回傳的是格式化後的字串(如 “10 GB”, “2 MB”),字串排序會導致 “10 GB” 排在 “2 MB” 前面。
解法:後端 API 除了回傳顯示用的字串,同時回傳原始 Bytes 數字 (sizeBytes),前端使用該數字進行精確排序。
部署與安全性
由於這是私有服務,我不希望將其暴露在公網而不加保護。與其在程式碼內寫複雜的登入系統,我選擇利用 Nginx Proxy Manager 的 Access Lists 功能。
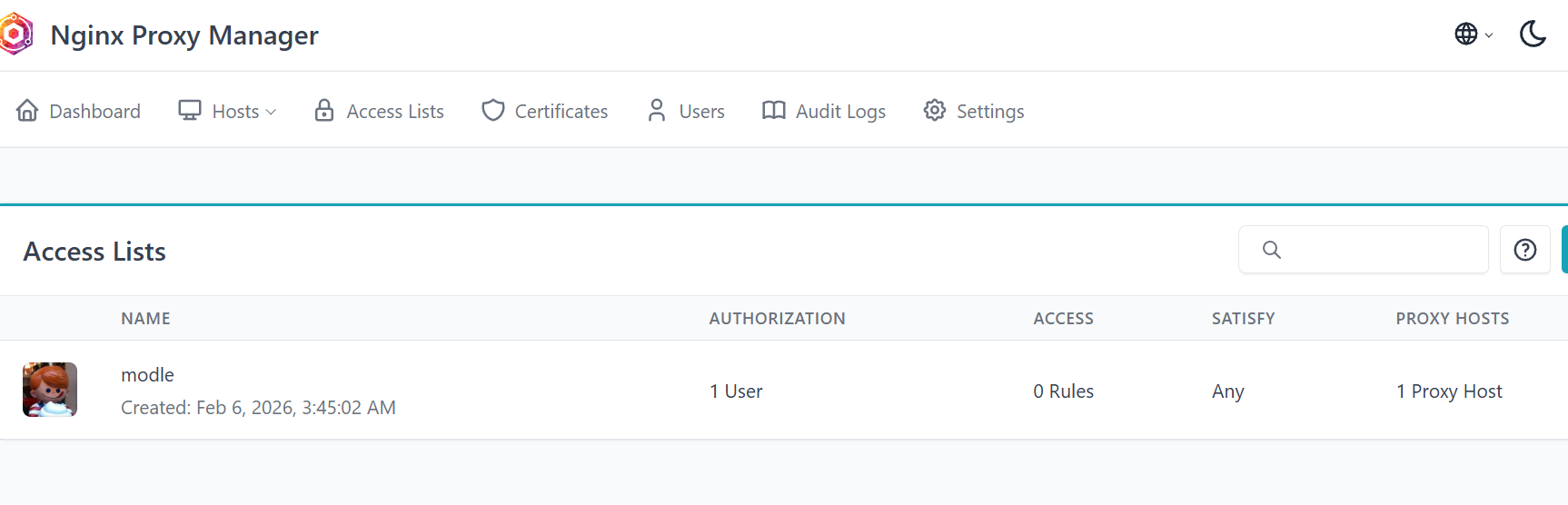
這是一個優雅的「無程式碼」解決方案:在 Nginx 層級攔截請求,彈出瀏覽器原生的帳號密碼視窗 (Basic Auth)。只有驗證通過的請求才會轉發給我的 Docker 容器,確保了絕對的安全。
結語
這個專案雖然不大,但涵蓋了 Full Stack 開發的精髓:從 Docker 環境建置、後端串流處理、前端狀態管理到反向代理設定。
如果你也有整理本地 LLM 的困擾,不妨試試看這個架構!
Tech Stack: React, Node.js, Python, Docker, Nginx GitHub: (GitHub連結)