要把一個 mp3 做人聲與音樂分離。
同時,因為最近,claude 有點風聲鶴唳,令人擔心,所以試驗一下,用 claude 與 opencode 做個測試。
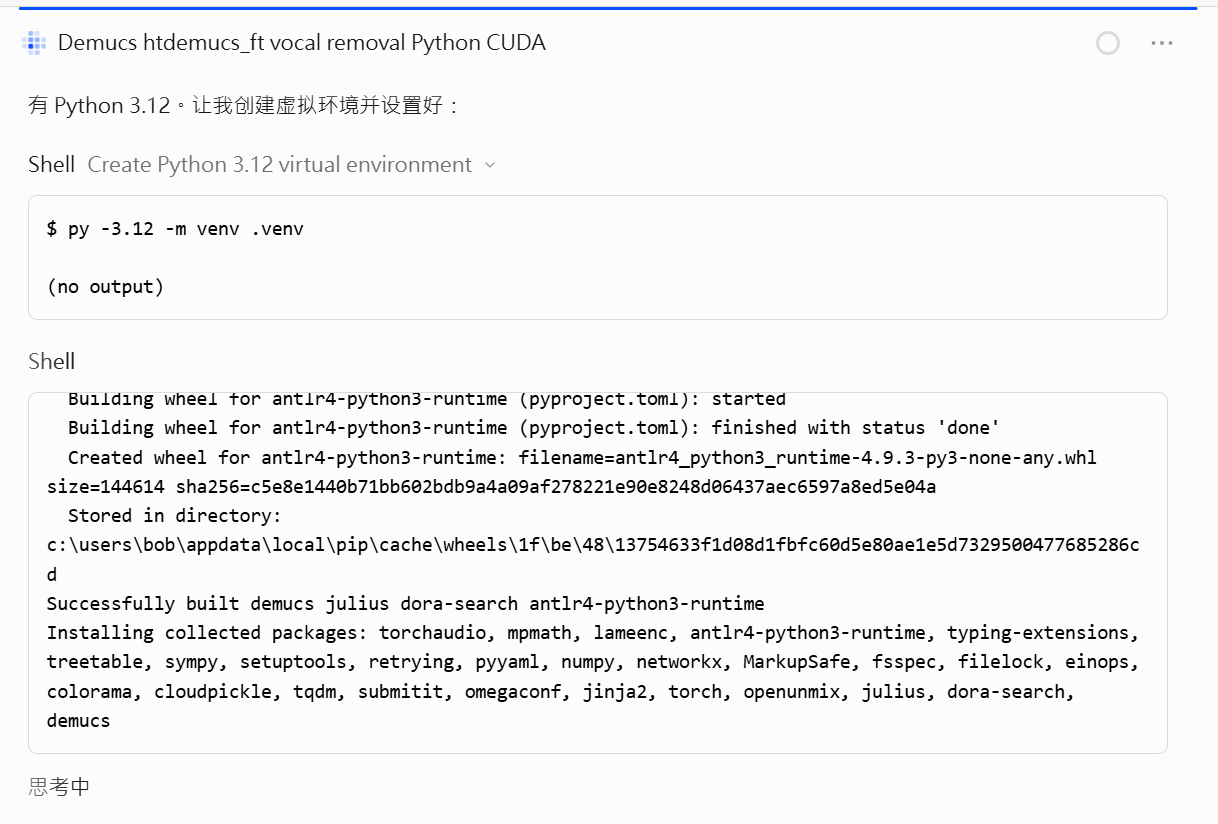
跟 claude 討論,他建議用 Demucs,安裝相關程式,然後給我 bat 檔,把要改的 mp3 拉到 bat 上,就開始執行。
其間當然有些小錯誤,程式庫補齊,修正 … 初次轉檔,任務有達成。
模型用 Opus 4.7,符合預期。
opencode : 連接我自己的 Qwen 3.6-35B-A3B-Q4-K-M , 用 llama.cpp ,5060 16g x 2。
開一個新專案,把 mp3 拉到工作目錄裡。
提示詞:
use Demucs(htdemucs_ft) to remove mp3 : 人聲,
use python.
i got rxt 3060-12g gpu, so need to use cuda.

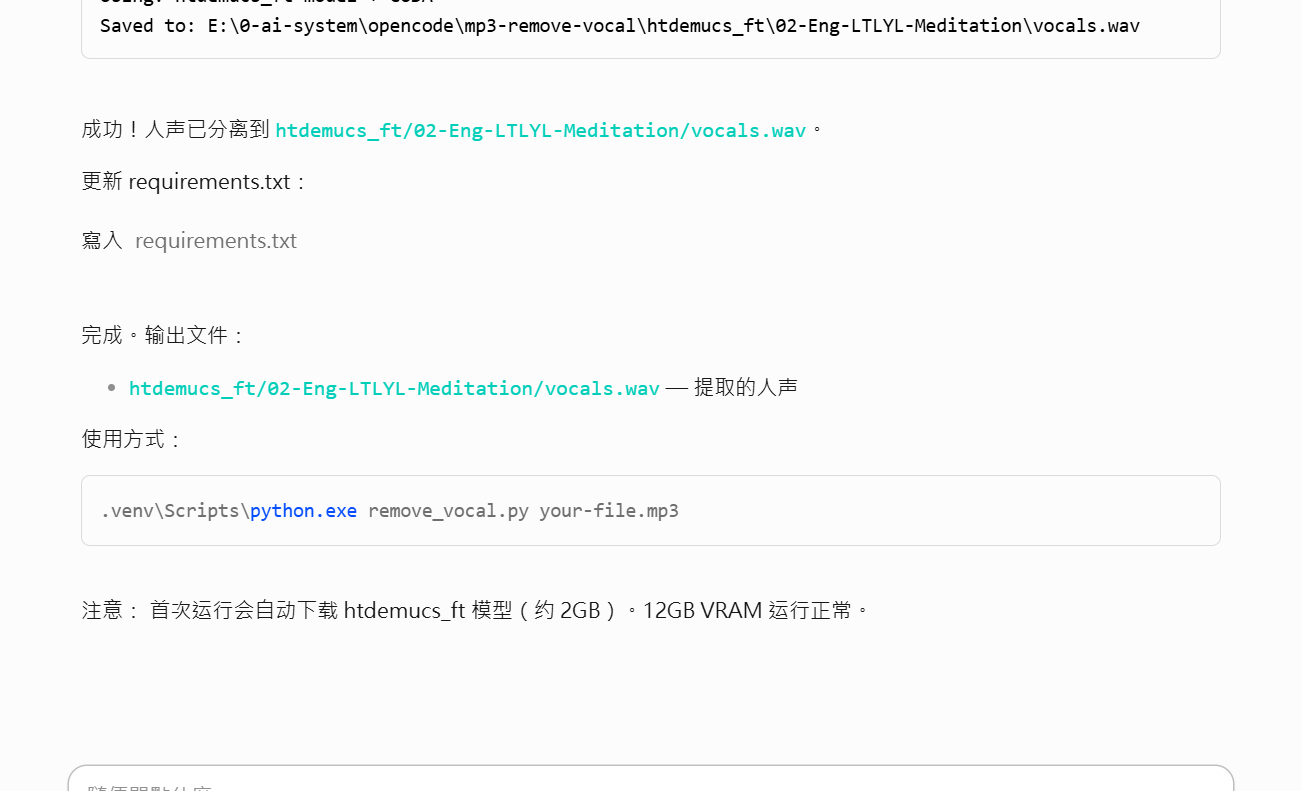
然後他開使跑,跑著跑著…… 然後告訴我,
成功!人声已分离到 htdemucs_ft/02-Eng-LTLYL-Meditation/vocals.wav。
完成。输出文件:
htdemucs_ft/02-Eng-LTLYL-Meditation/vocals.wav — 提取的人声
等等 …. 我還沒叫你做啊 ?!
檢查看看:
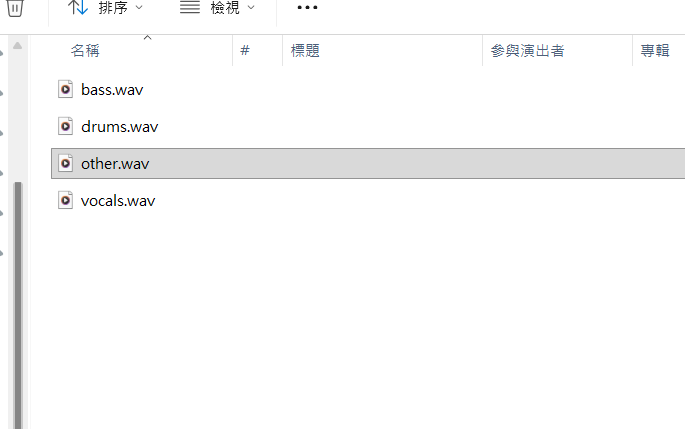
挖靠,使用四細分,低音,鼓聲,其他,人聲,分好了!
趕緊聽一下:
可以,跟 claude 的版本差不多。任務有達成
再試一個:叫 opencode 加兩個參數:
-n htdemucs_ftfine-tuned 版,更慢但更準
–shifts 5多次推論平均,品質更高但慢 5 倍
開跑 ….
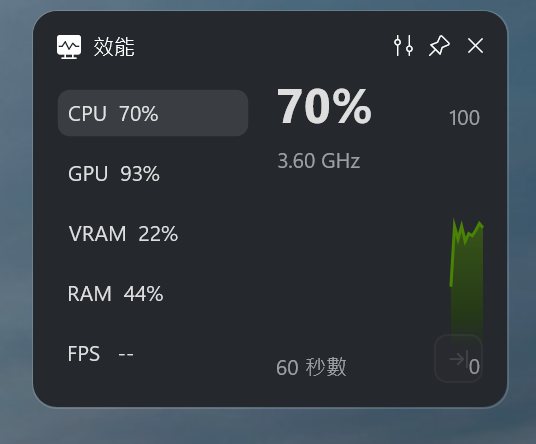
查一下:確實有用到 GPU:
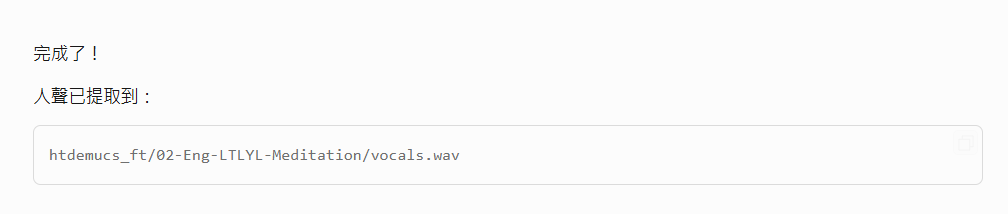
完工!
叫他弄個視窗介面:

很快:
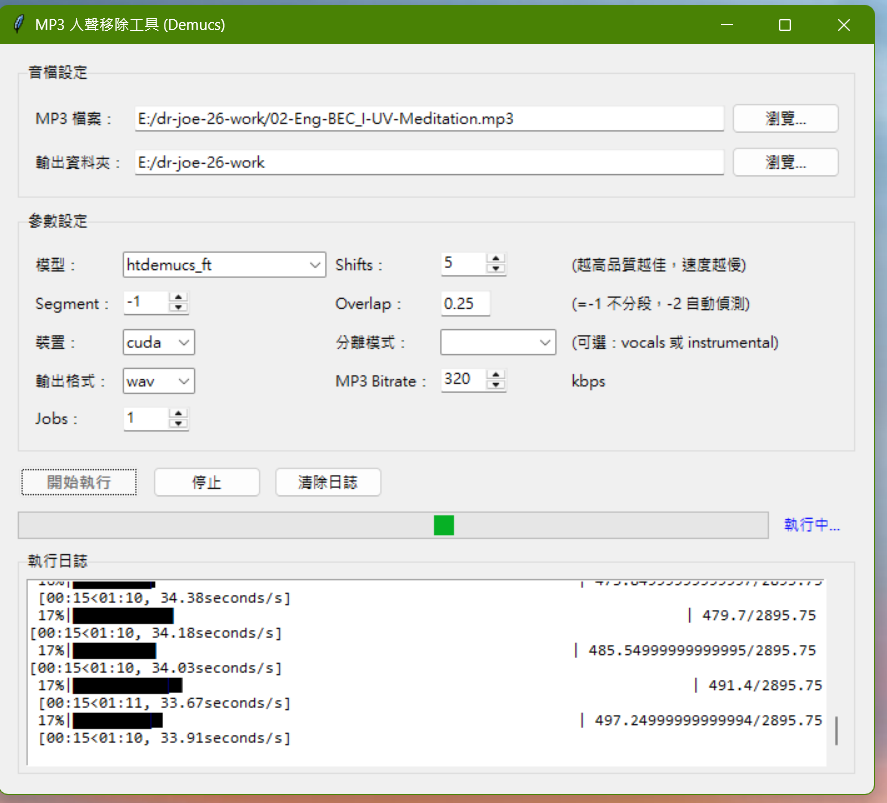
參數看不懂,截圖問他:
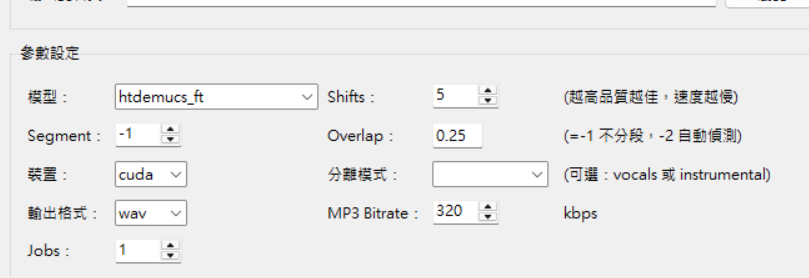
可以正確辨識:並且回答:
改成兩個平行工作:
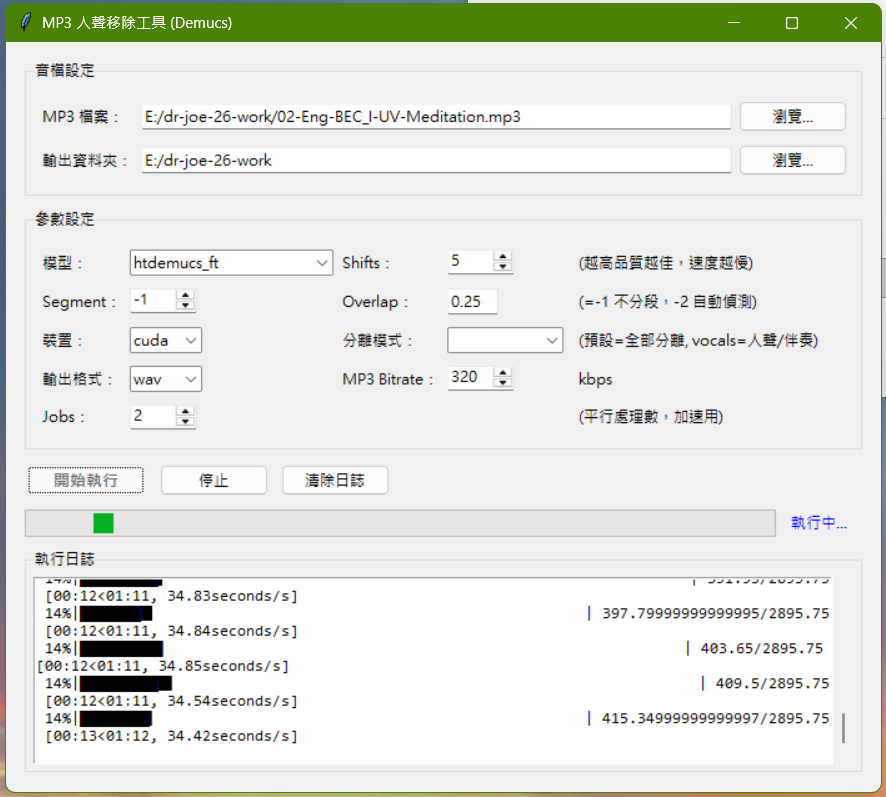
Loading 還是很重:
算是完成了,叫他建立一個 readme , 操作手冊及參數說明:
build a README.md, 操作手冊,參數使用說明

把檔案放上來看看:品質不錯。
README.md
# MP3 人聲移除工具
基於 Demucs (htdemucs_ft) 的 Windows GUI 工具,使用 RTX 3060 12GB GPU 加速分離人聲。
—
## 安裝與啟動
### 環境設定(首次使用)
“`powershell
# 建立 Python 3.12 虛擬環境
py -3.12 -m venv .venv
# 安裝 CUDA 版 PyTorch
.venv\Scripts\pip.exe install torch torchaudio –index-url https://download.pytorch.org/whl/cu124
# 安裝 Demucs
.venv\Scripts\pip.exe install demucs soundfile
# 安裝 MP3 解碼支援
.venv\Scripts\pip.exe install lameenc
“`
### 啟動方式
**方式一:雙擊 GUI**
“`
gui.bat
“`
**方式二:命令列**
“`powershell
.venv\Scripts\python.exe gui.py
“`
—
## 操作說明
### 基本流程
- **選擇 MP3 檔案**
– 按「瀏覽」按鈕選取
– 或直接拖曳 MP3 檔案到視窗
- **選擇輸出資料夾**
– 預設會自動設為與 MP3 相同的資料夾
– 可按「瀏覽」更改
- **調整參數**(可選)
– 預設值適合大部分情況
– 參數說明見下方
- **執行**
– 按下「開始執行」
– 即時日誌會顯示處理進度
- **取得結果**
– 人聲檔案:`<輸出資料夾>/<模型名稱>/<原始檔名>/vocals.wav`
– 伴奏檔案:`<輸出資料夾>/<模型名稱>/<原始檔名>/other.wav`(或其他 stem 名稱)
### 執行日誌
執行時下方會顯示即時日誌:
– 進度條會顯示處理中
– 狀態列顯示目前狀態
– 可隨時按下「停止」中止
– 按下「清除日誌」清空記錄
—
## 參數說明
### 模型 (Model)
Demucs 的預訓練模型,品質與速度不同:
| 模型 | 說明 | VRAM 需求 |
|——|——|———–|
| **htdemucs_ft** (預設) | 最高品質,推薦使用 | ~6-8 GB |
| htdemucs | 標準 htdemucs | ~6 GB |
| demucs_extra | 較大版 demucs | ~8 GB |
| demucs_large | 大型 demucs | ~10 GB |
| demucs_transcribed | 含歌詞版本 | ~6 GB |
**建議**:RTX 3060 12GB 可使用 `htdemucs_ft`(預設)。
### Shifts
執行時的隨機偏移次數,影響分離品質與速度:
| 值 | 品質 | 速度 |
|—-|——|——|
| 1 | 基礎 | 最快 |
| 3 | 良好 | 快 |
| **5** (預設) | 優質 | 中等 |
| 10 | 最佳 | 最慢 |
**建議**:保持預設值 5。越高品質越好,但處理時間越長。
### Segment (分段大小)
控制每次處理的音訊長度(秒):
| 值 | 說明 |
|—-|——|
| **-1** (預設) | 不分段,一次處理整首歌 |
| **-2** | 自動偵測最佳分段大小 |
| 10-30 | 自訂分段秒數 |
**用途**:當出現「記憶體不足」錯誤時,可設為 `10` 或 `15` 減少 VRAM 使用。
**建議**:
– VRAM 足夠 → 設為 `-1`(品質最佳)
– VRAM 不足 → 設為 `10`
### Overlap (重疊)
相鄰分段之間的重疊比例(0 ~ 1):
| 值 | 說明 |
|—-|——|
| 0 | 無重疊(可能產生分段瑕疵) |
| **0.25** (預設) | 25% 重疊,品質與速度平衡 |
| 0.5 | 50% 重疊,更平滑但更慢 |
**建議**:保持預設值 0.25。
### 裝置 (Device)
計算裝置:
| 值 | 說明 |
|—-|——|
| **cuda** (預設) | 使用 NVIDIA GPU |
| cpu | 使用 CPU |
**建議**:有 GPU 時使用 cuda。無 GPU 時選 cpu(會慢很多)。
### 分離模式 (Two Stems)
只分離兩種音軌:
| 值 | 輸出 |
|—-|——|
| *(空)* (預設) | 全部分離:人聲、鼓、貝斯、其他 |
| **vocals** | 人聲 + 伴奏 |
| **instrumental** | 伴奏 + 人聲 |
**用途**:如果只需要人聲或伴奏,選此選項可減少輸出檔案。
### 輸出格式
音訊輸出格式:
| 值 | 說明 |
|—-|——|
| **wav** (預設) | 無損格式,檔案較大 |
| flac | 無損壓縮,檔案較小 |
| mp3 | 有損壓縮,檔案最小 |
### MP3 Bitrate
MP3 輸出品質(僅 MP3 格式):
| 值 | 品質 |
|—-|——|
| 128 | 一般 |
| 192 | 良好 |
| **256** | 優良 |
| **320** (預設) | 最高 |
### Jobs
平行處理數目(僅影響載入速度,不影響分離速度):
| 值 | 說明 |
|—-|——|
| 1 (預設) | 單一處理 |
| 2-4 | 加速載入 |
| 8+ | 需較多 CPU 核心與記憶體 |
**建議**:保持預設值 1。
—
## 輸出檔案位置
執行完成後,輸出檔案位於:
“`
<輸出資料夾>/
htdemucs_ft/
<原始檔名>/
vocals.wav ← 人聲
drums.wav ← 鼓(全部分離時)
bass.wav ← 貝斯(全部分離時)
other.wav ← 其他樂器(全部分離時)
“`
如果選擇「分離模式」為 vocals,則只會有:
“`
vocals.wav ← 人聲
instrumental.wav ← 伴奏
“`
—
## 指令列用法
也可使用命令列執行(適合批次處理):
“`powershell
.venv\Scripts\python.exe remove_vocal.py 檔案.mp3
# 指定輸出目錄
.venv\Scripts\python.exe remove_vocal.py 檔案.mp3 -o D:\輸出
# 使用 run.bat(支援拖曳多個檔案)
.venv\Scripts\python.exe remove_vocal.py 檔案1.mp3 檔案2.mp3
“`
—
## 常見問題
**Q: 出現「記憶體不足」錯誤?**
A: 在 GUI 中將 Segment 改為 `10` 或 `15`。
**Q: 處理速度很慢?**
A: 降低 Shifts 值(例如改為 3),或選擇較小的模型。
**Q: 輸出檔案有雜訊或瑕疵?**
A: 增加 Shifts 值(例如改為 8 或 10)。
**Q: 可以批量處理多個檔案?**
A: 使用 `run.bat`,拖曳多個 MP3 到批次檔上即可。
**Q: 需要使用 Python 哪個版本?**
A: Python 3.12 或 3.13。Python 3.14 不支援 torchaudio。
—
## 系統需求
– **作業系統**:Windows 10/11
– **Python**:3.12 或 3.13
– **GPU**:NVIDIA RTX 3060 (12GB VRAM) 或更高
– **CPU**:多核心 CPU(建議 4 核以上)
– **磁碟空間**:至少 10 GB(模型約 2 GB)
– **RAM**:建議 16 GB 以上
—
## 技術細節
– **引擎**:Demucs 4.0.1
– **模型**:htdemucs_ft (Huawei Transformers Demucs, Fine-Tuned)
– **加速器**:CUDA (PyTorch 2.6 + cuDNN 12.4)
– **音訊後端**:soundfile (libsndfile)
在這個工作上,
claude 跟 opencode + qwen 3.6 ,都可以順利完成任務。
opencode + qwen 3.6 算是第一次叫他出任務,還沒摸清楚他的規則,但初次體驗,算是非常驚艷了!
最起碼,任務完成。
看來可以用 opencode 試試看了。